
Et eksempel på dette er rapporten som ble publisert i april, og som ser nærmere på KI språkmodeller og mulige teknologiske, sosio-økonomiske og politiske implikasjoner av disse språkmodeller. Rapporten legger frem policyoverveielser knyttet til AI-språkmodeller blant annet i lys av OECDs prinsipper for KI, med vekt på risikoer og etiske spørsmål som disse språkmodellene stiller oss overfor. Nedenfor følger et sammendrag av hovedpunktene i rapporten.
Hvordan fungerer språkmodeller som Chat GPT?
ChatGPT er etter hvert velkjent for de fleste av oss. Dette medfører også en offentlig og politisk debatt om konsekvenser og mulige skadevirkninger av kunstig intelligens (KI). KI språkmodeller (LM) er kjernen i mye brukte språkapplikasjoner som ChatGPT. Noe som gjør det er verdt å ta en nærmere titt på teknologien og dens implikasjoner for samfunnet.
I sin kjerne er språkmodeller statistiske prediktorer for det neste ordet eller ethvert annet språkelement gitt en sekvens av forutgående ord. Deres forskjellige applikasjoner inkluderer tekstutfylling, tekst-til-tale-konvertering, språkoversettelse, chatbots, virtuelle assistenter og talegjenkjenning. Modellene gjør det mulig for datamaskiner å behandle og generere menneskelig språk. De trenes opp på store mengder data ved hjelp av teknikker som spenner fra regelbaserte til statistiske modeller og dyp læring. For alle, unntatt de enkleste modellene, er deres interne operasjoner uklare: det er krevende å få en forståelse av hvordan de genererer tilsynelatende intelligente og menneskelignende utsagn over et bredt spekter av oppgaver.
Oversikt over nasjonal KI politikk og initiativer
Innledningsvis gir rapporten en oversikt over KI politikk og initiativ i en rekke OECD land for å utvikle grunnlag for nasjonale språkmodeller. Natural Language Processing (NLP) handler om dataprogrammer og verktøy som automatiserer funksjoner i naturlig språk ved å analysere, produsere, modifisere eller svare på menneskelig tekst og tale.
Dagens språkmodeller er i hovedsak basert på engelskspråklige tekster. Nasjonale myndigheter oppmuntrer og veileder utviklingen og implementeringen av NLP på nasjonalspråk. En trend er å investere i digitale språkressurser på ikke-engelske språk, inkludert mindre brukte og urfolksspråk. NLP forskningssentre og samarbeidsplattformer er opprettet med partnere fra privat sektor, akademia og sivilsamfunn. Flere initiativer over landegrensene tar sikte på å dele kunnskap og beste praksis og legge til rette for funksjonalitet mellom systemer basert på datasett på ulike nasjonalspråk. Figuren nedenfor – fra selskapet Huggin Face, som leverer datasett og verktøy for å utvikle apper basert på maskinlæring – illustrerer den dominerende stilling engelsk språk har i utvikling av språkmodeller.
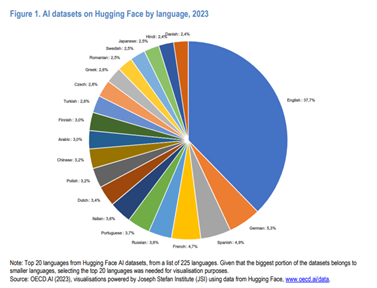
I den sammenheng nevner rapporten blant annet Nasjonalbibliotekets initiativ Språkbanken som utvikler og tilbyr store datasett med norsk tekst og tale. Samt de to Forskningsrådsfinansierte initiativene SCRIBE og CLARINO. Sistnevnte er en del av et europeisk infrastrukturprosjekt på området.
Utvikling av KI språkmodeller i et samfunnsperspektiv
Deretter vurderer rapporten teknologiske dimensjoner ved KI-språkteknologier gjennom OECD-rammeverket for klassifisering av AI-systemer. En ser blant annet nærmere på hvordan disse teknologiene påvirker mennesker og planeten, økonomisk kontekst, data og input, KI-modeller osv. Det gis en oversikt over tekniske komponenter i språkmodeller.
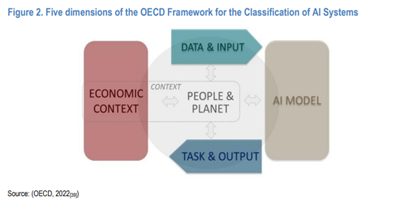
Rapporten peker på at språkmodellen tas i bruk i en rekke sammenhenger og har påvirkning på en rekke områder, herunder at den tas i bruk av aktører med begrenset KI kunnskap, per i dag er dominert av engelsk, høyst sannsynlig vil føre til automatisering av oppgaver som i dag gjøres manuelt og at også tilgangen til KI språkmodeller er ujevnt fordelt.
Den økonomiske betydningen av AI-språkteknologier antas å være stor og voksende. Store teknologiselskaper og AI-forskningsorganisasjoner – særlig i USA og Kina - er aktører i utvikling og utrulling av NLP-systemer. KI-språkmodeller har applikasjoner i mange sektorer og betydelig påvirkning. Eksempler er læring og bruk av språk gjennom applikasjoner som Duolingo og Grammarly.
KI språkmodeller er avhengig av betydelig mengder inndata i form av tekst. Utvelgelse og kuratering av disse dataene er avgjørende for utviklingen av mest mulig pålitelige språkmodeller. Det er viktig at utviklere vurderer både representativiteten og nøyaktigheten i de datasettene som brukes. Og at de vurderer om de er partiske/fordomsfulle (biased) eller inneholder personsensitive opplysninger.
NLP har eksistert siden 1940-tallet, men betydelige fremskritt har blitt gjort siden 2015, takket være store datasett og økt data/prosessorkapasitet. Såkalte nevrale nettverk har muliggjort imponerende resultater i naturlige språkoppgaver og har ført til utvikling av store språkmodeller (LLM). Dette er enkelt forklart et slags forsøk på imitasjon av hva som foregår i en menneskehjerne vet at et input går gjennom lag av såkalte parametere for så å komme med en prediksjon basert på dette. Deretter kan det sjekkes mot en fasit og kjøres tilbake for å justere parameterne. "Transformer" -arkitekturen som ble utviklet i 2017, var et kritisk gjennombrudd som muliggjorde kraftige LLM. Denne ble utviklet av flere store teknologiselskaper som Google og Amazon og effektiviserte nevrale nettverk ved å redusere tiden som trengtes til utregning og trening. Enkelte forskere ser nå på muligheten for at slik arkitektur kan bidra til å utvikle en «generell» KI modell med kapasitet til å gjøre en rekke ulike oppgaver.
Så langt har utviklingen av språkmodeller vært avhengig av store datasett, mange såkalte parametere og betydelig datakraft. Det byr på flere utfordringer både knyttet til etikk, miljø og personvern, og en ser nå en tendens i retning av å utvikle mindre språkmodeller med høy kvalitet basert på mer effektive treningsmetoder.
Implikasjoner for politikk
I siste kapittel drøfter rapporten mulige politikkimplikasjoner som følge av at LLM nå blir allment tilgjengelig. Drøftingen baserer seg på OECDs AI Principles fra 2019, og består at fem verdibaserte prinsipper og fem politikkanbefalinger:
De verdibaserte prinsippene går i korthet ut på at KI bør utvikles slik at det a) bidrar til inkluderende og bærekraftig vekst, b) på en måte som tar hensyn til menneskerettigheter, demokrati og rettsstat, c) sikrer at systemene er gjennomsiktige og forklarbare, med mulighet for innsikt i grunnlaget for output, d) er robuste og sikre og e) sikres ansvarlig for KI løsningene og dens resultater.
Rapporten utdyper så implikasjonene av disse prinsippene når det gjelder språkmodeller. Blant annet pekes det på at disse modellene baserer seg på nevrale nettverk – som blant annet innebærer sofistikerte statistiske modellteknikker og stor kompleksitet. Dette gjør dem ugjennomsiktige, og selv utviklerne av modellene er ute av stand til å forklare hvordan variablene kombineres for å komme til resultatet. Slike nettverk refereres derfor ofte til som «svarte bokser».
De fem politikkanbefalingene i rapporten er i korte trekk følgende: a) det bør legges til rette for offentlige og private investeringer som bidrar til å utvikle pålitelig KI, b) myndigheter bør fremme tilgjengelige økosystemer for KI, med digital infrastruktur, teknologi og mekanismer for å dele data og kunnskap, c) myndighetene bør legge til rette for politikk og regulatoriske rammer som legger til rette for utvikling og introduksjon av pålitelig KI, d) en må forberede seg på de endringer KI vil innebære for arbeidsliv og samfunn, blant annet gjennom å utstyre befolkningen med nødvendig kunnskap og kompetanse og e) det bør samarbeides internasjonalt for å dele kunnskap og utvikle standarder som bidrar til pålitelig KI.
Også her utdyper rapporten de konkrete implikasjonene for språkmodeller av de mer generelle KI politikkanbefalingene. Eksempelvis pekes det på viktigheten av datamaskinkapasitet for å unngå at noen få store aktører får en alt for dominerende posisjon, utvikling av data og modeller for andre språk enn engelsk, behovet for investeringer i mer energieffektive løsninger og politikk som bidrar til å utvikle kompetanse og kunnskap for å håndtere overgangen til økonomi, arbeidsliv og samfunn hvor KI spiller en langt mer dominerende rolle.